Drawing raster maps with ggmap
library(tidyverse)
library(ggmap)
library(RColorBrewer)
library(patchwork)
library(here)
options(digits = 3)
set.seed(1234)
theme_set(theme_minimal())
ggmap is a package for R that retrieves raster map tiles from online mapping services like Google Maps and plots them using the ggplot2 framework. The map tiles are raster because they are static image files generated previously by the mapping service. You do not need any data files containing information on things like scale, projection, boundaries, etc. because that information is already created by the map tile. This severely limits your ability to redraw or change the appearance of the geographic map, however the tradeoff means you can immediately focus on incorporating additional data into the map.
Obtain map images
ggmap supports open-source map providers such as OpenStreetMap and Stamen Maps, as well as the proprietary Google Maps. Obtaining map tiles requires use of the get_map() function. There are two formats for specifying the mapping region you wish to obtain:
- Bounding box
- Center/zoom
Specifying map regions
Bounding box
Bounding box requires the user to specify the four corners of the box defining the map region. For instance, to obtain a map of Chicago using Stamen Maps:
# store bounding box coordinates
chi_bb <- c(
left = -87.936287,
bottom = 41.679835,
right = -87.447052,
top = 42.000835
)
chicago_stamen <- get_stamenmap(
bbox = chi_bb,
zoom = 11
)
chicago_stamen
## 627x712 terrain map image from Stamen Maps.
## See ?ggmap to plot it.
To view the map, use ggmap():
ggmap(chicago_stamen)
The zoom argument in get_stamenmap() controls the level of detail in the map. The larger the number, the greater the detail.
get_stamenmap(
bbox = chi_bb,
zoom = 12
) %>%
ggmap()
The smaller the number, the lesser the detail.
get_stamenmap(
bbox = chi_bb,
zoom = 10
) %>%
ggmap()
Trial and error will help you decide on the appropriate level of detail depending on what data you need to visualize on the map.
Center/zoom
While Stamen Maps and OpenStreetMap require the bounding box format for obtaining map tiles and allow you to increase or decrease the level of detail within a single bounding box, Google Maps requires specifying the center coordinate of the map (a single longitude/latitude location) and the level of zoom or detail. zoom is an integer value from 3 (continent) to 21 (building). This means the level of detail is hardcoded to the size of the mapping region. The default zoom level is 10.
# store center coordinate
chi_center <- c(lon = -87.65, lat = 41.855)
chicago_google <- get_googlemap(center = chi_center)
ggmap(chicago_google)
get_googlemap(
center = chi_center,
zoom = 12
) %>%
ggmap()
get_googlemap(
center = chi_center,
zoom = 8
) %>%
ggmap()
Types of map tiles
Each map tile provider offers a range of different types of maps depending on the background you want for the map. Stamen Maps offers several different types:
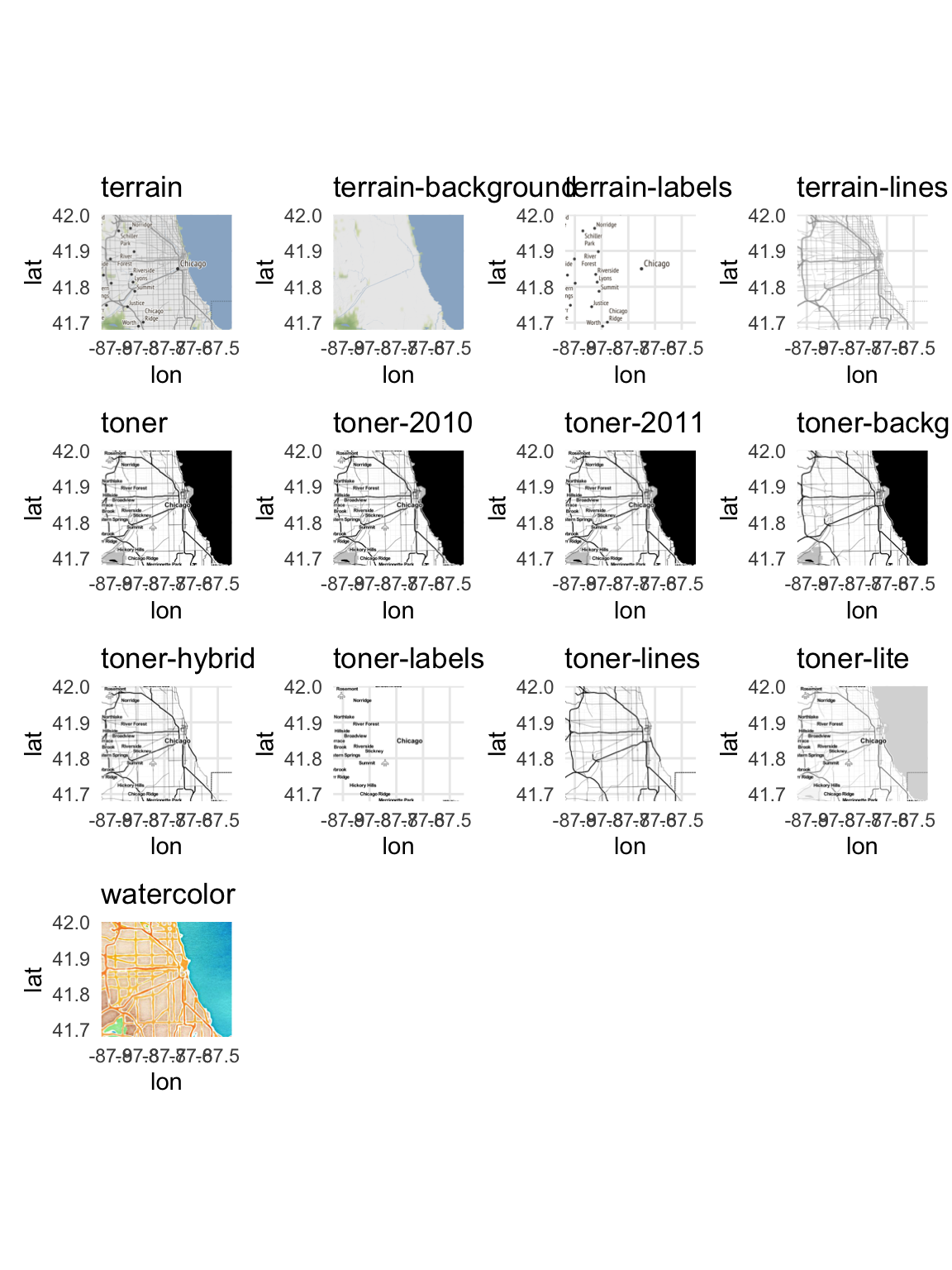
Google Maps is a bit more limited, but still offers a few major types:
See the documentation for the get_*map() function for the exact code necessary to get each type of map.
get_map() is a wrapper that automatically queries Google Maps, OpenStreetMap, or Stamen Maps depending on the function arguments and inputs. While useful, it also combines all the different arguments of get_googlemap(), get_stamenmap(), and getopenstreetmap() and can become a bit jumbled. Use at your own risk.Import crime data
Now that we can obtain map tiles and draw them using ggmap(), let’s explore how to add data to the map. The city of Chicago has an excellent data portal publishing a large volume of public records. Here we’ll look at crime data from 2017.1 I previously downloaded a .csv file containing all the records, which I import using read_csv():
crimes <- read_csv("https://info5940.infosci.cornell.edu/data/Crimes_-_2017.csv") to download the file from the course website.crimes <- here("static", "data", "Crimes_-_2017.csv") %>%
read_csv()
glimpse(crimes)
## Rows: 267,345
## Columns: 22
## $ ID <dbl> 11094370, 11118031, 11134189, 11156462, 1116487…
## $ `Case Number` <chr> "JA440032", "JA470589", "JA491697", "JA521389",…
## $ Date <chr> "09/21/2017 12:15:00 AM", "10/12/2017 07:14:00 …
## $ Block <chr> "072XX N CALIFORNIA AVE", "055XX W GRAND AVE", …
## $ IUCR <chr> "1122", "1345", "4651", "1110", "0265", "143A",…
## $ `Primary Type` <chr> "DECEPTIVE PRACTICE", "CRIMINAL DAMAGE", "OTHER…
## $ Description <chr> "COUNTERFEIT CHECK", "TO CITY OF CHICAGO PROPER…
## $ `Location Description` <chr> "CURRENCY EXCHANGE", "JAIL / LOCK-UP FACILITY",…
## $ Arrest <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE,…
## $ Domestic <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE…
## $ Beat <chr> "2411", "2515", "0922", "2514", "1221", "0232",…
## $ District <chr> "024", "025", "009", "025", "012", "002", "005"…
## $ Ward <dbl> 50, 29, 12, 30, 32, 20, 9, 12, 12, 27, 32, 17, …
## $ `Community Area` <dbl> 2, 19, 58, 19, 24, 40, 49, 30, 30, 23, 24, 44, …
## $ `FBI Code` <chr> "10", "14", "26", "11", "02", "15", "03", "06",…
## $ `X Coordinate` <dbl> 1156443, 1138788, 1159425, 1138653, 1161264, 11…
## $ `Y Coordinate` <dbl> 1947707, 1913480, 1875711, 1920720, 1905292, 18…
## $ Year <dbl> 2017, 2017, 2017, 2017, 2017, 2017, 2017, 2017,…
## $ `Updated On` <chr> "03/01/2018 03:52:35 PM", "03/01/2018 03:52:35 …
## $ Latitude <dbl> 42.0, 41.9, 41.8, 41.9, 41.9, 41.8, 41.7, 41.8,…
## $ Longitude <dbl> -87.7, -87.8, -87.7, -87.8, -87.7, -87.6, -87.6…
## $ Location <chr> "(42.012293397, -87.699714109)", "(41.918711651…
Each row of the data frame is a single reported incident of crime. Geographic location is encoded in several ways, though most importantly for us the exact longitude and latitude of the incident is encoded in the Longitude and Latitude columns respectively.
Plot high-level map of crime
Let’s start with a simple high-level overview of reported crime in Chicago. First we need a map for the entire city.
chicago <- chicago_stamen
ggmap(chicago)
Using geom_point()
Since each row is a single reported incident of crime, we could use geom_point() to map the location of every crime in the dataset. Because ggmap() uses the map tiles (here, defined by chicago) as the basic input, we specify data and mapping inside of geom_point(), rather than inside ggplot():
ggmap(chicago) +
geom_point(
data = crimes,
mapping = aes(
x = Longitude,
y = Latitude
)
)
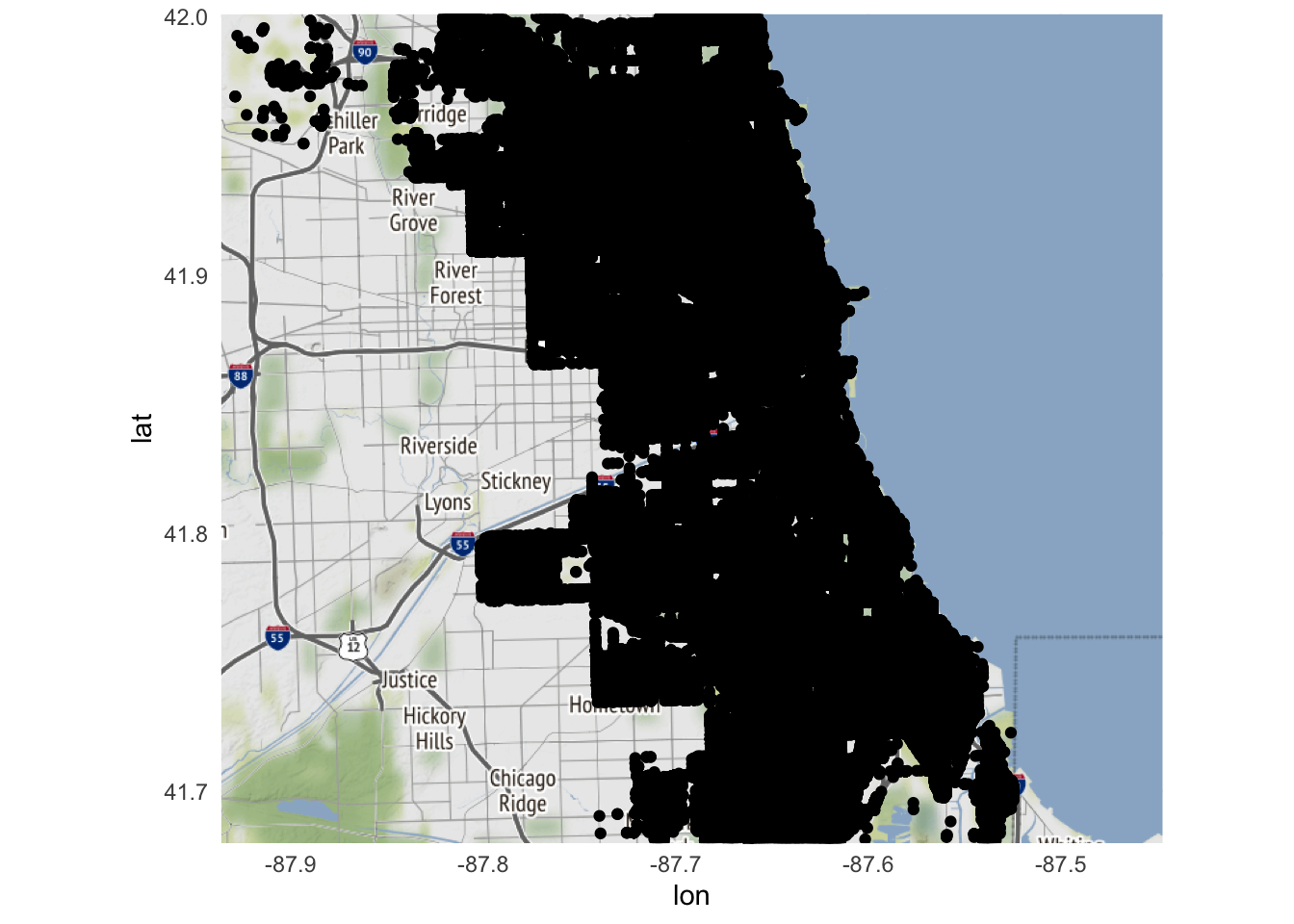
What went wrong? All we get is a sea of black.
nrow(crimes)
## [1] 267345
Oh yeah. There were 267345 reported incidents of crime in the city. Each incident is represented by a dot on the map. How can we make this map more usable? One option is to decrease the size and increase the transparancy of each data point so dense clusters of crime become apparent:
ggmap(chicago) +
geom_point(
data = crimes,
aes(
x = Longitude,
y = Latitude
),
size = .25,
alpha = .01
)
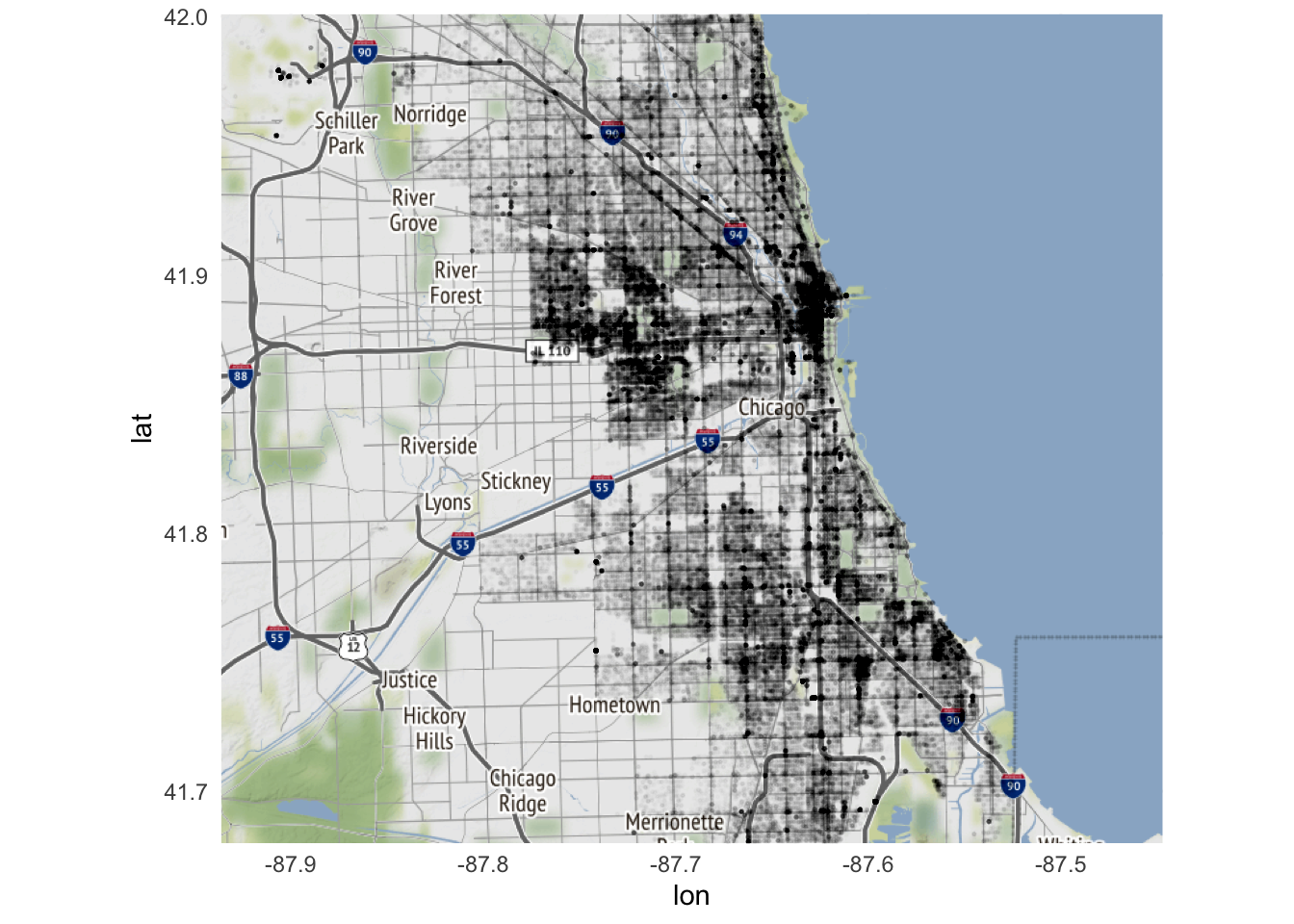
Better, but still not quite as useful as it could be.
Using stat_density_2d()
Instead of relying on geom_point() and plotting the raw data, a better approach is to create a heatmap. More precisely, this will be a two-dimensional kernel density estimation (KDE). In this context, KDE will take all the raw data (i.e. reported incidents of crime) and convert it into a smoothed plot showing geographic concentrations of crime. The core function in ggplot2 to generate this kind of plot is geom_density_2d():
ggmap(chicago) +
geom_density_2d(
data = crimes,
aes(
x = Longitude,
y = Latitude
)
)
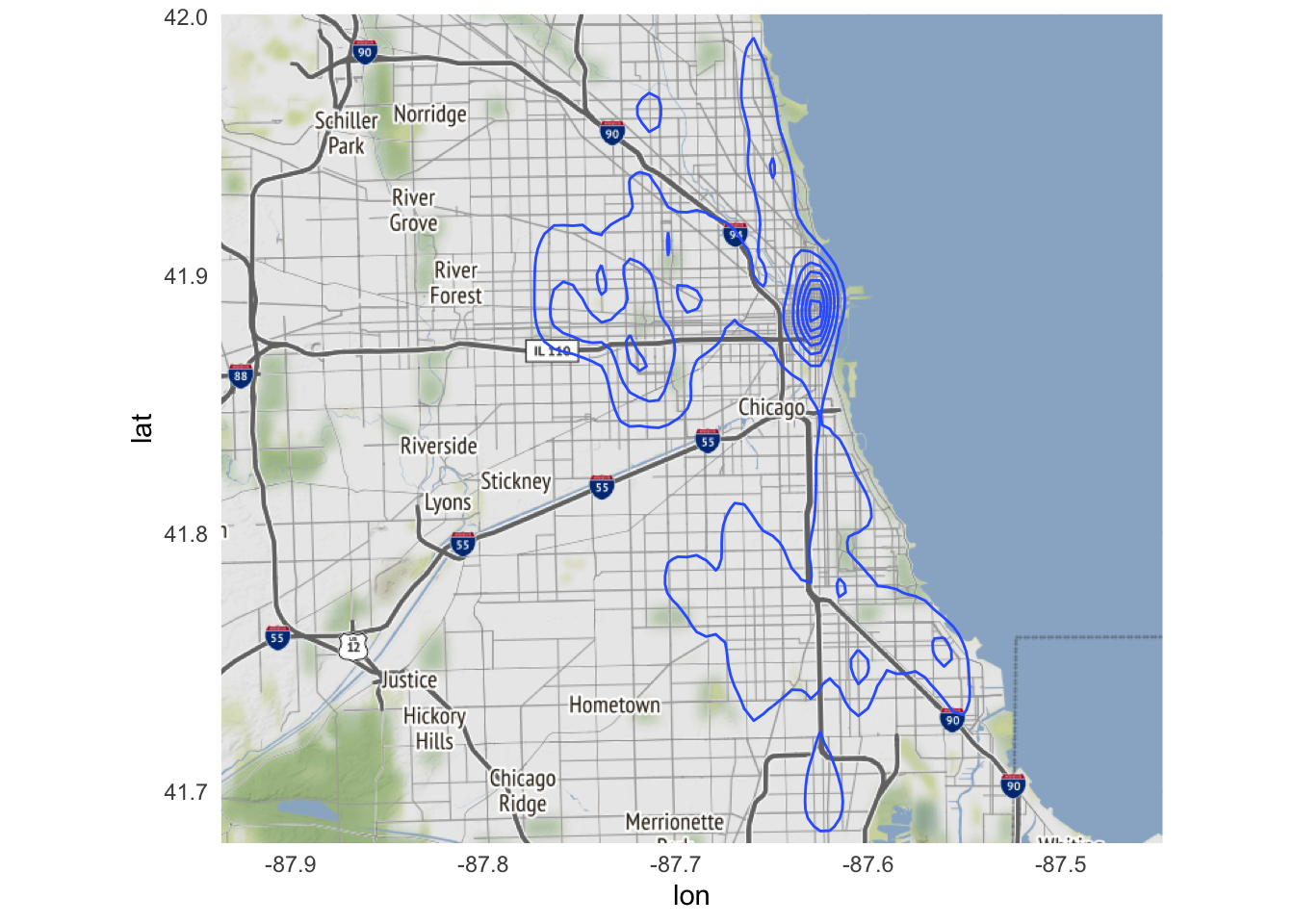
By default, geom_density_2d() draws a contour plot with lines of constant value. That is, each line represents approximately the same frequency of crime all along that specific line. Contour plots are frequently used in maps (known as topographic maps) to denote elevation.
](/media/contour-map_hua50b97a337ebf4f1ff2f376bc62271a6_306658_5c7db9d53ef3ad3cd21905cf4ee15aeb.webp)
Rather than drawing lines, instead we can fill in the graph so that we use the fill aesthetic to draw bands of crime density. To do that, we use the related function stat_density_2d():
ggmap(chicago) +
stat_density_2d(
data = crimes,
aes(
x = Longitude,
y = Latitude,
fill = stat(level)
),
geom = "polygon"
)
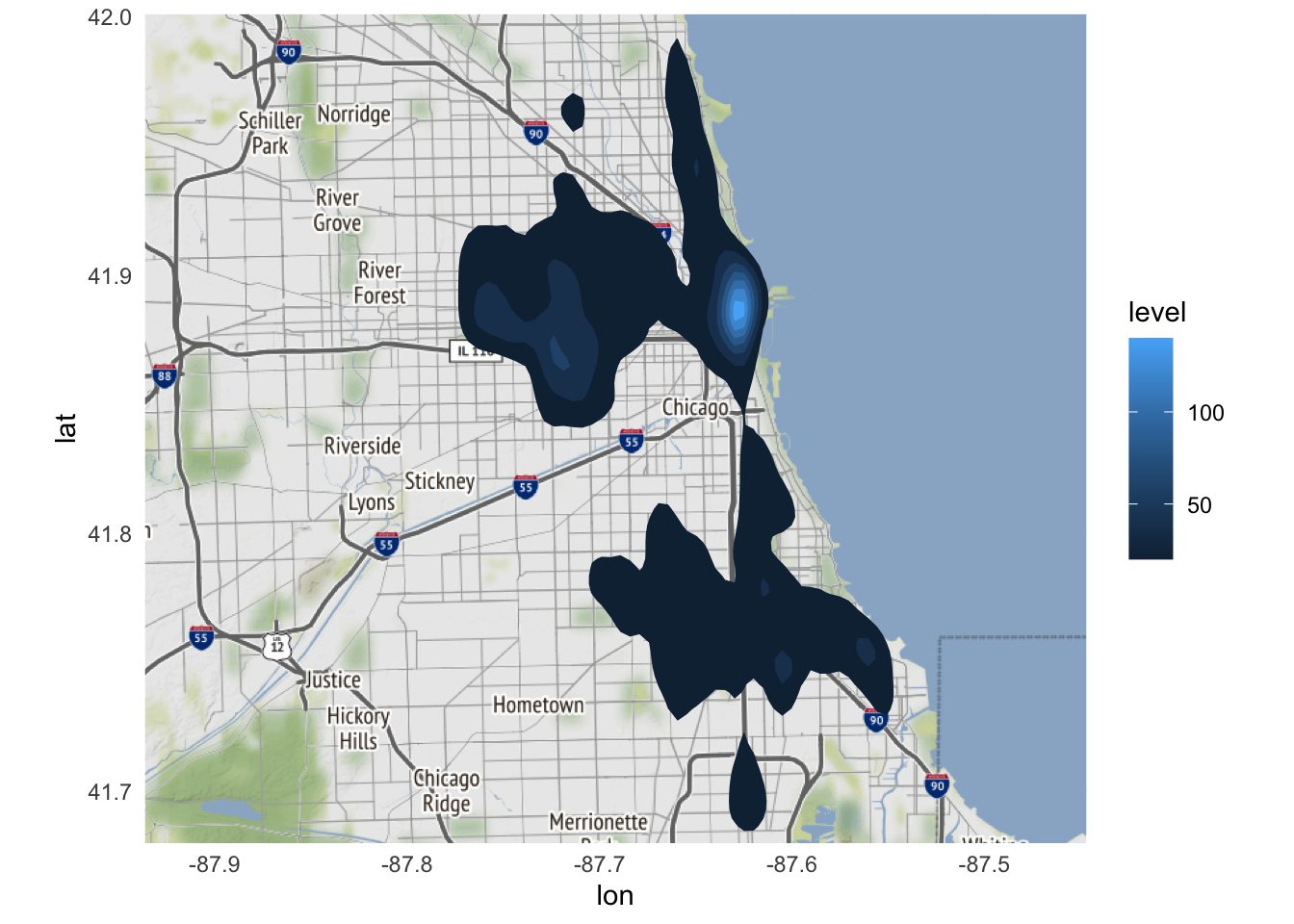
Note the two new arguments:
geom = "polygon"- change the geometric object to be drawn from adensity_2dgeom to apolygongeomfill = stat(level)- the value for thefillaesthetic is thelevelcalculated withinstat_density_2d(), which we access using thestat()notation.
This is an improvement, but we can adjust some additional settings to make the graph visually more useful. Specifically,
- Increase the number of
bins, or unique bands of color allowed on the graph - Make the heatmap semi-transparent using
alphaso we can still view the underlying map - Change the color palette to better distinguish between high and low crime areas. Here I use
brewer.pal()from theRColorBrewerpackage to create a custom color palette using reds and yellows.
ggmap(chicago) +
stat_density_2d(
data = crimes,
aes(
x = Longitude,
y = Latitude,
fill = stat(level)
),
alpha = .2,
bins = 25,
geom = "polygon"
) +
scale_fill_gradientn(colors = brewer.pal(7, "YlOrRd"))
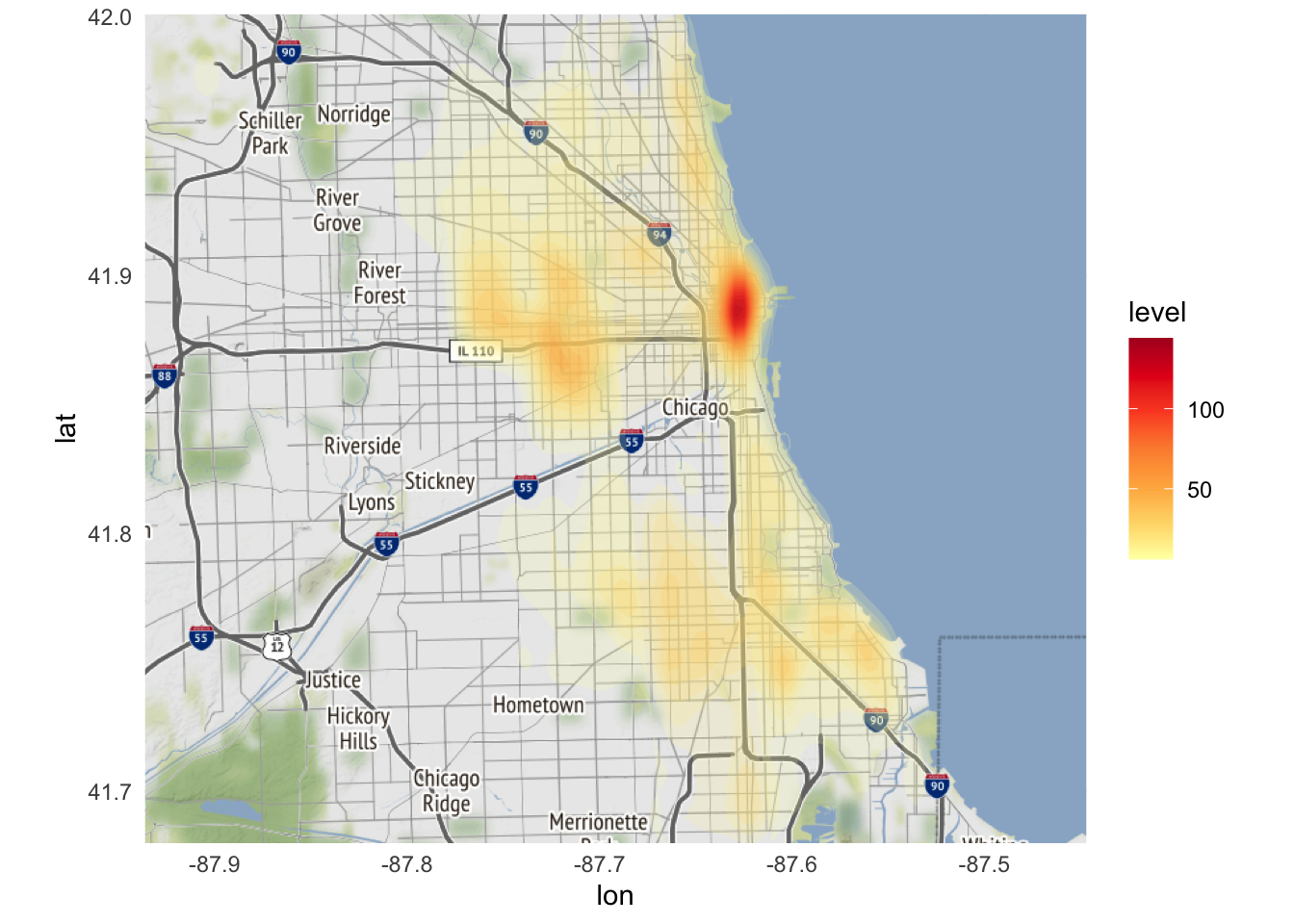
From this map, a couple trends are noticeable:
- The downtown region has the highest crime incidence rate. Not surprising given its population density during the workday.
- There are clusters of crime on the south and west sides. Also not surprising if you know anything about the city of Chicago.
Looking for variation
Because ggmap is built on ggplot2, we can use the core features of ggplot2 to modify the graph. One major feature is faceting. Let’s focus our analysis on four types of crimes with similar frequency of reported incidents2 and facet by type of crime:
ggmap(chicago) +
stat_density_2d(
data = crimes %>%
filter(`Primary Type` %in% c(
"BURGLARY", "MOTOR VEHICLE THEFT",
"NARCOTICS", "ROBBERY"
)),
aes(
x = Longitude,
y = Latitude,
fill = stat(level)
),
alpha = .4,
bins = 10,
geom = "polygon"
) +
scale_fill_gradientn(colors = brewer.pal(7, "YlOrRd")) +
facet_wrap(facets = vars(`Primary Type`))
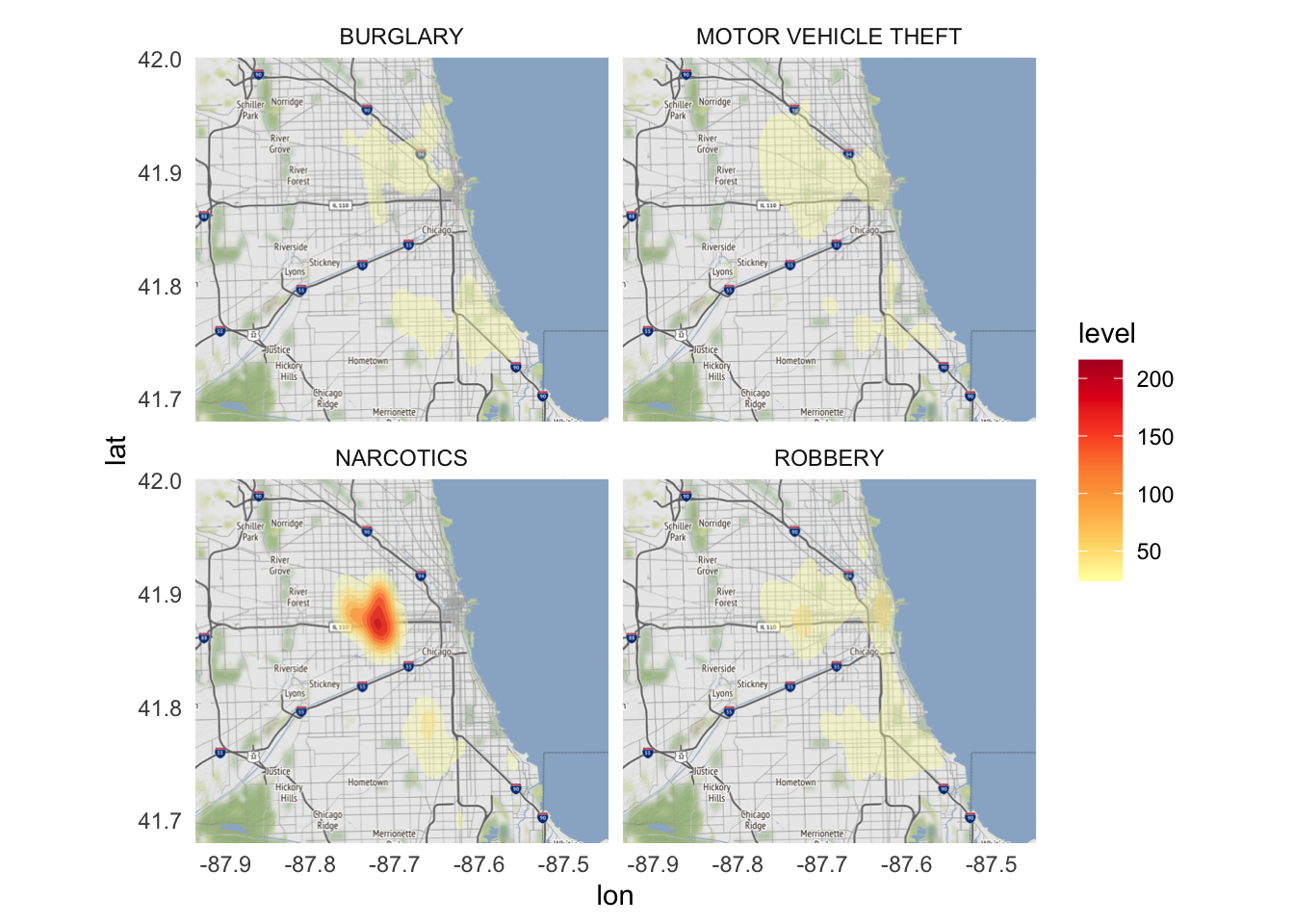
There is a large difference in the geographic density of narcotics crimes relative to the other catgories. While burglaries, motor vehicle thefts, and robberies are reasonably prevalent all across the city, the vast majority of narcotics crimes occur in the west and south sides of the city.
Locations of murders
While geom_point() was not appropriate for graphing a large number of observations in a dense geographic location, it does work rather well for less dense areas. Now let’s limit our analysis strictly to reported incidents of homicide in 2017.
(homicides <- crimes %>%
filter(`Primary Type` == "HOMICIDE"))
## # A tibble: 671 × 22
## ID Case …¹ Date Block IUCR Prima…² Descr…³ Locat…⁴ Arrest Domes…⁵ Beat
## <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <lgl> <lgl> <chr>
## 1 2.31e4 JA1496… 02/1… 001X… 0110 HOMICI… FIRST … ALLEY TRUE FALSE 1512
## 2 2.39e4 JA5309… 11/3… 088X… 0110 HOMICI… FIRST … APARTM… FALSE FALSE 0424
## 3 2.34e4 JA3024… 06/1… 047X… 0110 HOMICI… FIRST … STREET TRUE FALSE 0931
## 4 2.34e4 JA3124… 06/1… 006X… 0110 HOMICI… FIRST … STREET TRUE FALSE 0631
## 5 2.37e4 JA4900… 10/2… 048X… 0110 HOMICI… FIRST … APARTM… TRUE TRUE 1624
## 6 2.32e4 JA2107… 04/0… 013X… 0110 HOMICI… FIRST … APARTM… TRUE TRUE 1011
## 7 2.36e4 JA4619… 10/0… 018X… 0110 HOMICI… FIRST … STREET TRUE FALSE 1233
## 8 2.36e4 JA4619… 10/0… 018X… 0110 HOMICI… FIRST … STREET TRUE FALSE 1233
## 9 1.08e7 JA1383… 02/0… 013X… 0142 HOMICI… RECKLE… STREET TRUE FALSE 1022
## 10 2.35e4 JA3645… 07/2… 047X… 0110 HOMICI… FIRST … ALLEY TRUE FALSE 1113
## # … with 661 more rows, 11 more variables: District <chr>, Ward <dbl>,
## # `Community Area` <dbl>, `FBI Code` <chr>, `X Coordinate` <dbl>,
## # `Y Coordinate` <dbl>, Year <dbl>, `Updated On` <chr>, Latitude <dbl>,
## # Longitude <dbl>, Location <chr>, and abbreviated variable names
## # ¹`Case Number`, ²`Primary Type`, ³Description, ⁴`Location Description`,
## # ⁵Domestic
## # ℹ Use `print(n = ...)` to see more rows, and `colnames()` to see all variable names
We can draw a map of the city with all homicides indicated on the map using geom_point():
ggmap(chicago) +
geom_point(
data = homicides,
mapping = aes(
x = Longitude,
y = Latitude
),
size = 1
)
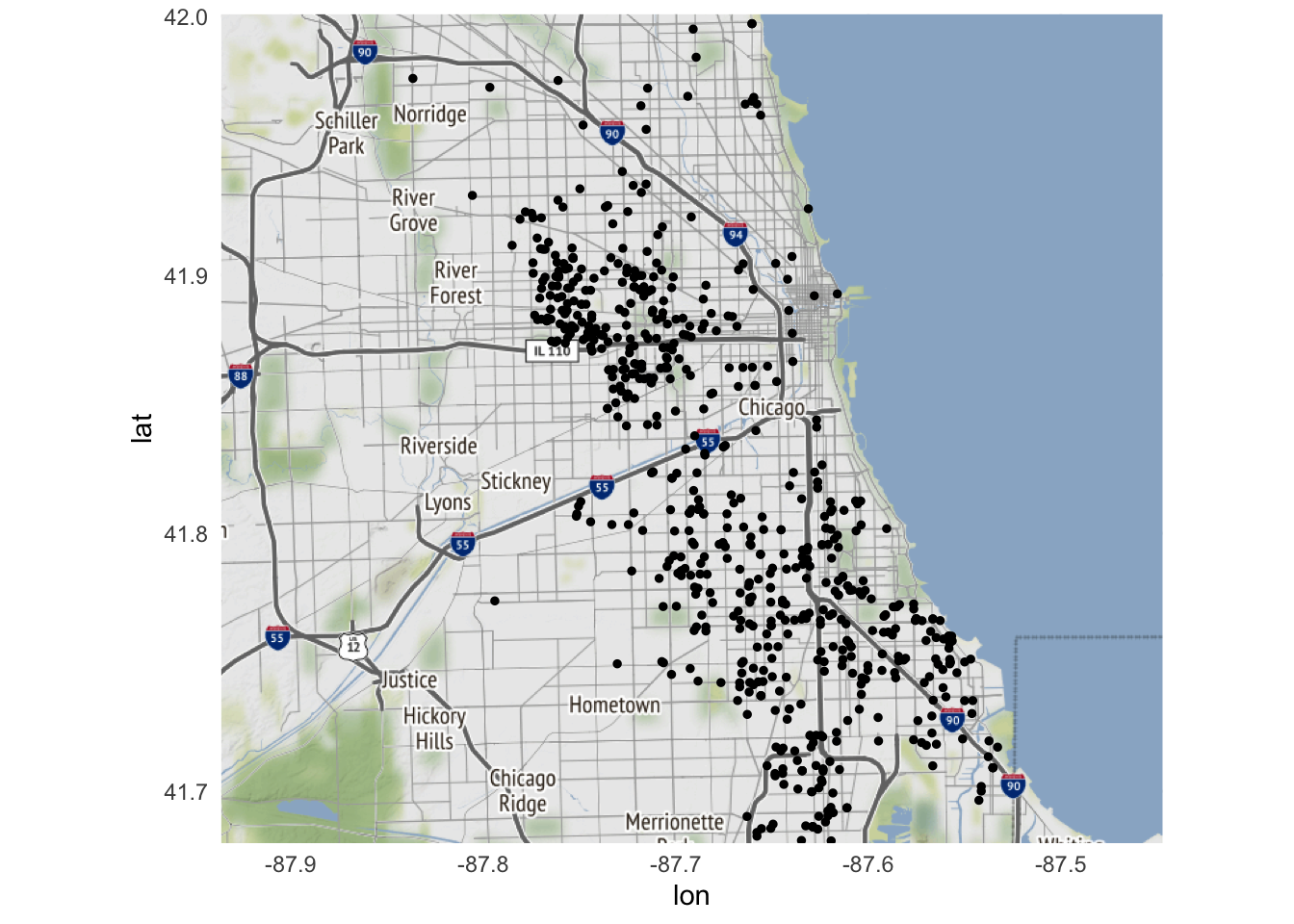
Compared to our previous overviews, few if any homicides are reported downtown. We can also narrow down the geographic location to map specific neighborhoods in Chicago. First we obtain map tiles for those specific regions. Here we’ll examine North Lawndale and Kenwood.
# North Lawndale is the highest homicides in 2017
# Compare to Kenwood
north_lawndale_bb <- c(
left = -87.749047,
bottom = 41.840185,
right = -87.687893,
top = 41.879850
)
north_lawndale <- get_stamenmap(
bbox = north_lawndale_bb,
zoom = 14
)
kenwood_bb <- c(
left = -87.613113,
bottom = 41.799215,
right = -87.582536,
top = 41.819064
)
kenwood <- get_stamenmap(
bbox = kenwood_bb,
zoom = 15
)
ggmap(north_lawndale)
ggmap(kenwood)
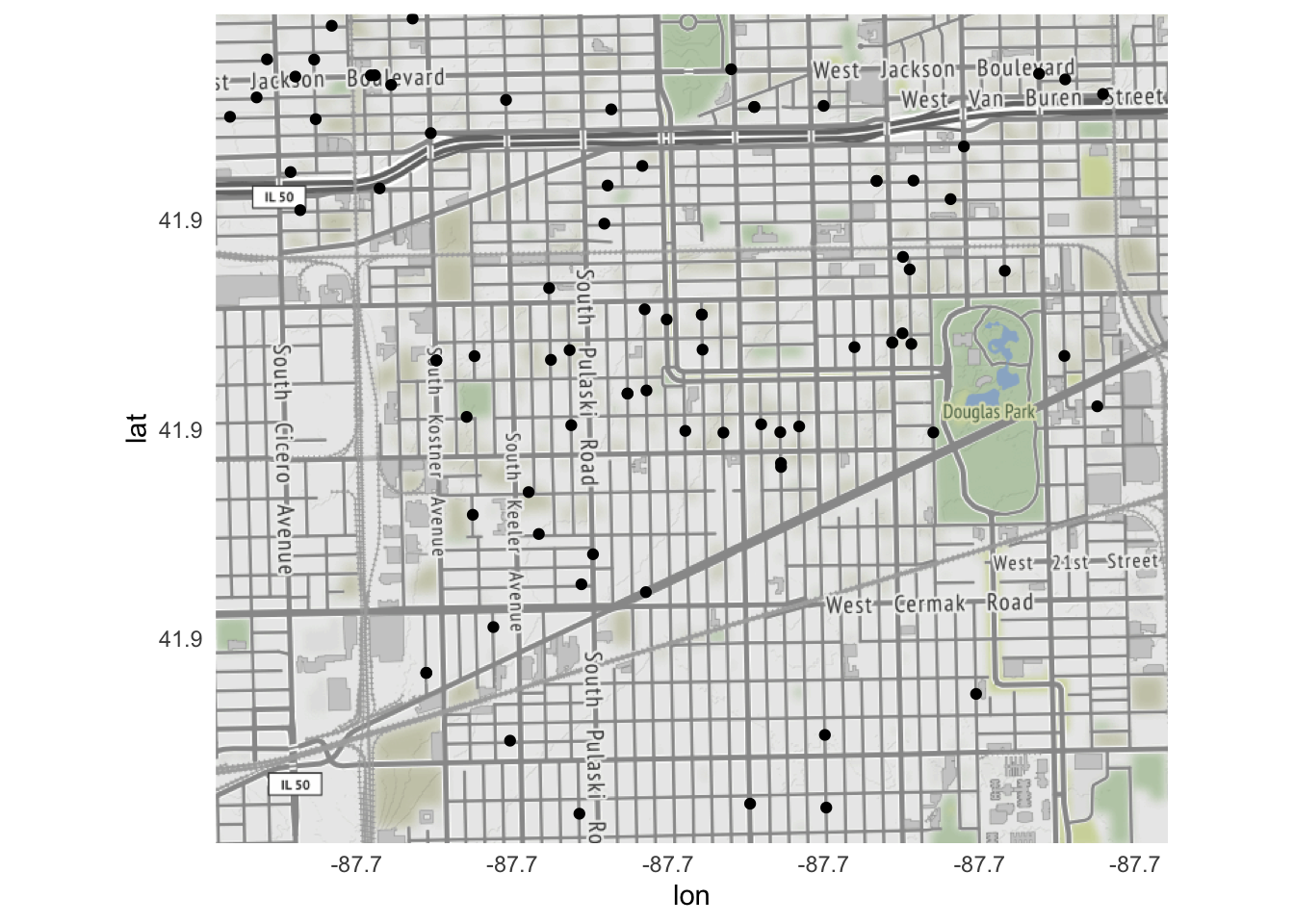
To plot homicides specifically in these neighborhoods, change ggmap(chicago) to the appropriate map tile:
ggmap(north_lawndale) +
geom_point(
data = homicides,
aes(x = Longitude, y = Latitude)
)
ggmap(kenwood) +
geom_point(
data = homicides,
aes(x = Longitude, y = Latitude)
)
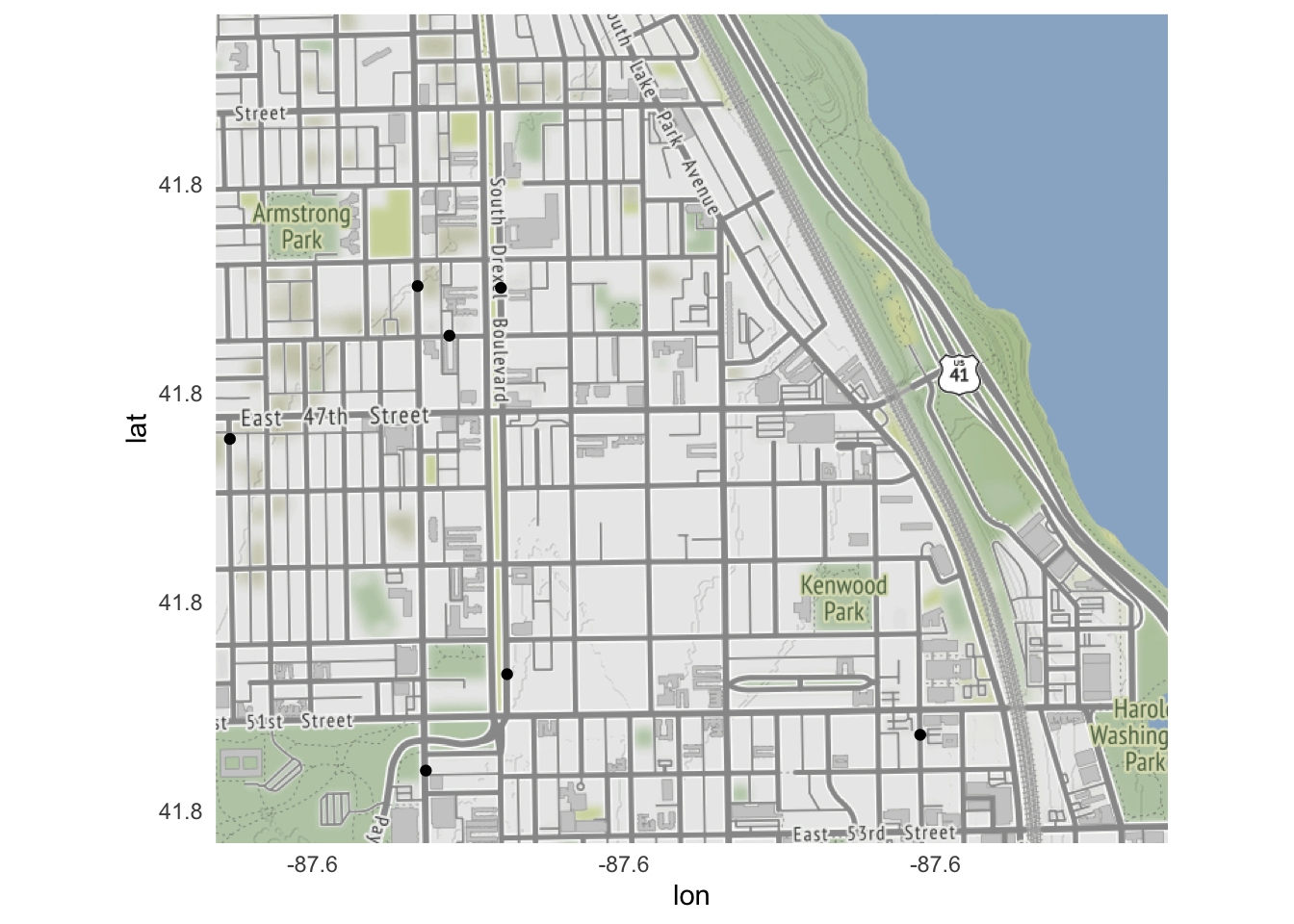
North Lawndale had the most reported homicides in 2017, whereas Kenwood had only a handful. And even though homicides contained data for homicides across the entire city, ggmap() automatically cropped the graph to keep just the homicides that occurred within the bounding box.
All the other aesthetic customizations of geom_point() work with ggmap. So we could expand these neighborhood maps to include all violent crime categories3 and distinguish each type by color:
(violent <- crimes %>%
filter(`Primary Type` %in% c(
"HOMICIDE",
"CRIM SEXUAL ASSAULT",
"ROBBERY"
)))
## # A tibble: 14,146 × 22
## ID Case …¹ Date Block IUCR Prima…² Descr…³ Locat…⁴ Arrest Domes…⁵ Beat
## <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <lgl> <lgl> <chr>
## 1 1.12e7 JA5319… 12/0… 022X… 0265 CRIM S… AGGRAV… STREET TRUE FALSE 1221
## 2 1.10e7 JA3223… 06/2… 003X… 031A ROBBERY ARMED:… SMALL … TRUE FALSE 0511
## 3 1.12e7 JA5459… 12/1… 007X… 031A ROBBERY ARMED:… SIDEWA… TRUE FALSE 1221
## 4 1.12e7 JA5467… 12/1… 007X… 031A ROBBERY ARMED:… STREET TRUE FALSE 1221
## 5 1.12e7 JB1471… 10/0… 092X… 0281 CRIM S… NON-AG… RESIDE… FALSE FALSE 2222
## 6 1.12e7 JB1475… 08/2… 001X… 0281 CRIM S… NON-AG… HOTEL/… FALSE FALSE 0122
## 7 2.31e4 JA1496… 02/1… 001X… 0110 HOMICI… FIRST … ALLEY TRUE FALSE 1512
## 8 1.10e7 JA3785… 08/0… 038X… 0313 ROBBERY ARMED:… SIDEWA… TRUE FALSE 1133
## 9 1.12e7 JA5386… 12/0… 092X… 031A ROBBERY ARMED:… SIDEWA… TRUE FALSE 0633
## 10 1.12e7 JB1496… 12/2… 005X… 0330 ROBBERY AGGRAV… CONVEN… FALSE FALSE 0123
## # … with 14,136 more rows, 11 more variables: District <chr>, Ward <dbl>,
## # `Community Area` <dbl>, `FBI Code` <chr>, `X Coordinate` <dbl>,
## # `Y Coordinate` <dbl>, Year <dbl>, `Updated On` <chr>, Latitude <dbl>,
## # Longitude <dbl>, Location <chr>, and abbreviated variable names
## # ¹`Case Number`, ²`Primary Type`, ³Description, ⁴`Location Description`,
## # ⁵Domestic
## # ℹ Use `print(n = ...)` to see more rows, and `colnames()` to see all variable names
ggmap(north_lawndale) +
geom_point(
data = violent,
aes(
x = Longitude, y = Latitude,
color = `Primary Type`
)
) +
scale_color_brewer(type = "qual", palette = "Dark2")
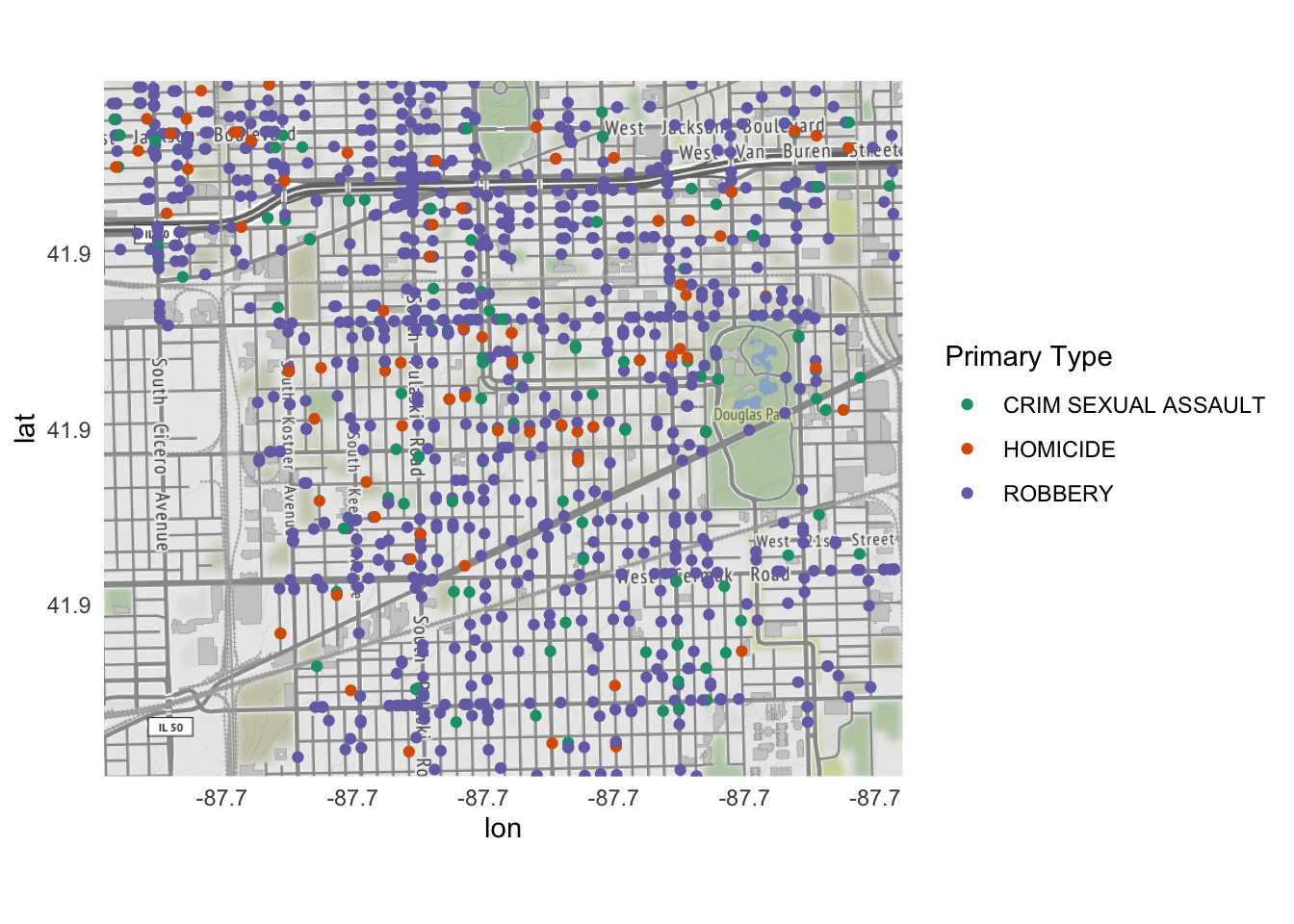
ggmap(kenwood) +
geom_point(
data = violent,
aes(
x = Longitude, y = Latitude,
color = `Primary Type`
)
) +
scale_color_brewer(type = "qual", palette = "Dark2")
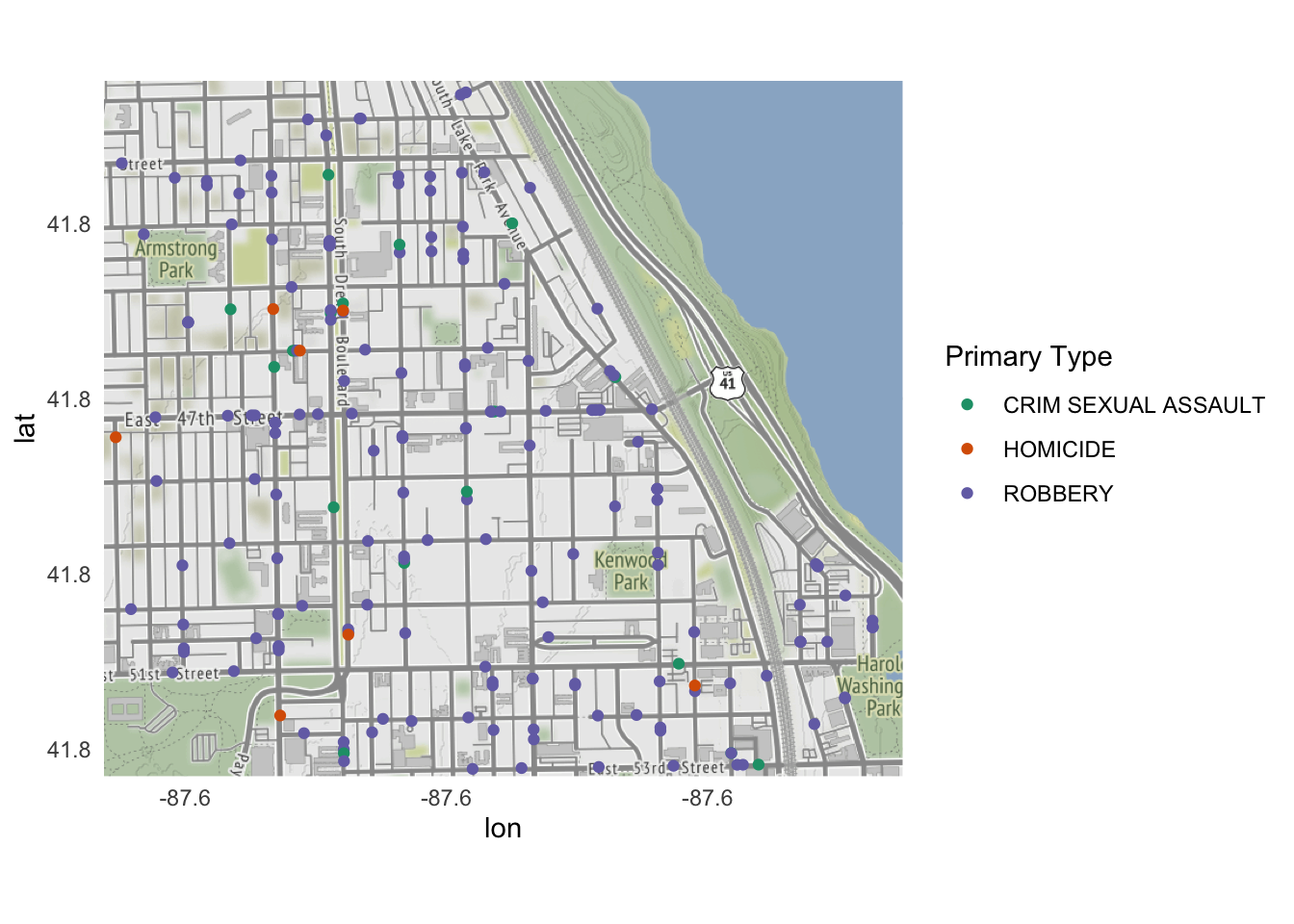
Additional resources
Session Info
sessioninfo::session_info()
## ─ Session info ───────────────────────────────────────────────────────────────
## setting value
## version R version 4.2.1 (2022-06-23)
## os macOS Monterey 12.3
## system aarch64, darwin20
## ui X11
## language (EN)
## collate en_US.UTF-8
## ctype en_US.UTF-8
## tz America/New_York
## date 2022-08-22
## pandoc 2.18 @ /Applications/RStudio.app/Contents/MacOS/quarto/bin/tools/ (via rmarkdown)
##
## ─ Packages ───────────────────────────────────────────────────────────────────
## package * version date (UTC) lib source
## assertthat 0.2.1 2019-03-21 [2] CRAN (R 4.2.0)
## backports 1.4.1 2021-12-13 [2] CRAN (R 4.2.0)
## bitops 1.0-7 2021-04-24 [2] CRAN (R 4.2.0)
## blogdown 1.10 2022-05-10 [2] CRAN (R 4.2.0)
## bookdown 0.27 2022-06-14 [2] CRAN (R 4.2.0)
## broom 1.0.0 2022-07-01 [2] CRAN (R 4.2.0)
## bslib 0.4.0 2022-07-16 [2] CRAN (R 4.2.0)
## cachem 1.0.6 2021-08-19 [2] CRAN (R 4.2.0)
## cellranger 1.1.0 2016-07-27 [2] CRAN (R 4.2.0)
## cli 3.3.0 2022-04-25 [2] CRAN (R 4.2.0)
## colorspace 2.0-3 2022-02-21 [2] CRAN (R 4.2.0)
## crayon 1.5.1 2022-03-26 [2] CRAN (R 4.2.0)
## DBI 1.1.3 2022-06-18 [2] CRAN (R 4.2.0)
## dbplyr 2.2.1 2022-06-27 [2] CRAN (R 4.2.0)
## digest 0.6.29 2021-12-01 [2] CRAN (R 4.2.0)
## dplyr * 1.0.9 2022-04-28 [2] CRAN (R 4.2.0)
## ellipsis 0.3.2 2021-04-29 [2] CRAN (R 4.2.0)
## evaluate 0.16 2022-08-09 [1] CRAN (R 4.2.1)
## fansi 1.0.3 2022-03-24 [2] CRAN (R 4.2.0)
## fastmap 1.1.0 2021-01-25 [2] CRAN (R 4.2.0)
## forcats * 0.5.1 2021-01-27 [2] CRAN (R 4.2.0)
## fs 1.5.2 2021-12-08 [2] CRAN (R 4.2.0)
## gargle 1.2.0 2021-07-02 [2] CRAN (R 4.2.0)
## generics 0.1.3 2022-07-05 [2] CRAN (R 4.2.0)
## ggmap * 3.0.0 2019-02-05 [2] CRAN (R 4.2.0)
## ggplot2 * 3.3.6 2022-05-03 [2] CRAN (R 4.2.0)
## glue 1.6.2 2022-02-24 [2] CRAN (R 4.2.0)
## googledrive 2.0.0 2021-07-08 [2] CRAN (R 4.2.0)
## googlesheets4 1.0.0 2021-07-21 [2] CRAN (R 4.2.0)
## gtable 0.3.0 2019-03-25 [2] CRAN (R 4.2.0)
## haven 2.5.0 2022-04-15 [2] CRAN (R 4.2.0)
## here * 1.0.1 2020-12-13 [2] CRAN (R 4.2.0)
## hms 1.1.1 2021-09-26 [2] CRAN (R 4.2.0)
## htmltools 0.5.3 2022-07-18 [2] CRAN (R 4.2.0)
## httr 1.4.3 2022-05-04 [2] CRAN (R 4.2.0)
## jpeg 0.1-9 2021-07-24 [2] CRAN (R 4.2.0)
## jquerylib 0.1.4 2021-04-26 [2] CRAN (R 4.2.0)
## jsonlite 1.8.0 2022-02-22 [2] CRAN (R 4.2.0)
## knitr 1.39 2022-04-26 [2] CRAN (R 4.2.0)
## lattice 0.20-45 2021-09-22 [2] CRAN (R 4.2.1)
## lifecycle 1.0.1 2021-09-24 [2] CRAN (R 4.2.0)
## lubridate 1.8.0 2021-10-07 [2] CRAN (R 4.2.0)
## magrittr 2.0.3 2022-03-30 [2] CRAN (R 4.2.0)
## modelr 0.1.8 2020-05-19 [2] CRAN (R 4.2.0)
## munsell 0.5.0 2018-06-12 [2] CRAN (R 4.2.0)
## patchwork * 1.1.1 2020-12-17 [2] CRAN (R 4.2.0)
## pillar 1.8.0 2022-07-18 [2] CRAN (R 4.2.0)
## pkgconfig 2.0.3 2019-09-22 [2] CRAN (R 4.2.0)
## plyr 1.8.7 2022-03-24 [2] CRAN (R 4.2.0)
## png 0.1-7 2013-12-03 [2] CRAN (R 4.2.0)
## purrr * 0.3.4 2020-04-17 [2] CRAN (R 4.2.0)
## R6 2.5.1 2021-08-19 [2] CRAN (R 4.2.0)
## RColorBrewer * 1.1-3 2022-04-03 [2] CRAN (R 4.2.0)
## Rcpp 1.0.9 2022-07-08 [2] CRAN (R 4.2.0)
## readr * 2.1.2 2022-01-30 [2] CRAN (R 4.2.0)
## readxl 1.4.0 2022-03-28 [2] CRAN (R 4.2.0)
## reprex 2.0.1.9000 2022-08-10 [1] Github (tidyverse/reprex@6d3ad07)
## RgoogleMaps 1.4.5.3 2020-02-12 [2] CRAN (R 4.2.0)
## rjson 0.2.21 2022-01-09 [2] CRAN (R 4.2.0)
## rlang 1.0.4 2022-07-12 [2] CRAN (R 4.2.0)
## rmarkdown 2.14 2022-04-25 [2] CRAN (R 4.2.0)
## rprojroot 2.0.3 2022-04-02 [2] CRAN (R 4.2.0)
## rstudioapi 0.13 2020-11-12 [2] CRAN (R 4.2.0)
## rvest 1.0.2 2021-10-16 [2] CRAN (R 4.2.0)
## sass 0.4.2 2022-07-16 [2] CRAN (R 4.2.0)
## scales 1.2.0 2022-04-13 [2] CRAN (R 4.2.0)
## sessioninfo 1.2.2 2021-12-06 [2] CRAN (R 4.2.0)
## sp 1.5-0 2022-06-05 [2] CRAN (R 4.2.0)
## stringi 1.7.8 2022-07-11 [2] CRAN (R 4.2.0)
## stringr * 1.4.0 2019-02-10 [2] CRAN (R 4.2.0)
## tibble * 3.1.8 2022-07-22 [2] CRAN (R 4.2.0)
## tidyr * 1.2.0 2022-02-01 [2] CRAN (R 4.2.0)
## tidyselect 1.1.2 2022-02-21 [2] CRAN (R 4.2.0)
## tidyverse * 1.3.2 2022-07-18 [2] CRAN (R 4.2.0)
## tzdb 0.3.0 2022-03-28 [2] CRAN (R 4.2.0)
## utf8 1.2.2 2021-07-24 [2] CRAN (R 4.2.0)
## vctrs 0.4.1 2022-04-13 [2] CRAN (R 4.2.0)
## withr 2.5.0 2022-03-03 [2] CRAN (R 4.2.0)
## xfun 0.31 2022-05-10 [1] CRAN (R 4.2.0)
## xml2 1.3.3 2021-11-30 [2] CRAN (R 4.2.0)
## yaml 2.3.5 2022-02-21 [2] CRAN (R 4.2.0)
##
## [1] /Users/soltoffbc/Library/R/arm64/4.2/library
## [2] /Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/library
##
## ──────────────────────────────────────────────────────────────────────────────
Full documentation of the data from the larger 2001-present crime dataset.. ↩︎
Specifically burglary, motor vehicle theft, narcotics, and robbery. ↩︎
Specifcally homicides, criminal sexual assault, and robbery. Aggravated assault and aggravated robbery are also defined as violent crimes by the Chicago Police Departmant, but the coding system for this data set does not distinguish between ordinary and aggravated types of assault and robbery. ↩︎